DNA of Things (DoT)
Storing data into DNA, 3D printed objects, plants, and more!
Sounds like Internet of Things? Maybe a bit more exciting?

Before getting too hyped, the reason why you’d love to store any kind of digital data into DNA is because of two main reasons: it is the most compact medium storage that we have found so far, and the most efficient one in the long run.
For the first one, let’s just remember that we are made up of millions of microscopic cells, each one of these very tiny things, follow the instructions of DNA, which is even more microscopic. Even so, DNA contains all the necessary information to make us who we are. From our hair color, to our lifespan, *DNA is the king.
Then what I mean when I say “the long run” is that, if kept in optimal conditions, DNA can last up to (literally) thousands of years. You’ve probably heard of those times in which researchers extract DNA from neanderthals, mammoths, or other ancient beings. That’s the proof that DNA can last for long… really long.
As you we can see, DNA already stores a bunch of information in every living thing. So what’s different? Well, in the XXI century, we’re giving this molecule a different, yet interesting enough purpose: storing digital data!
The digital era
Every time that I think about the past, I feel like I’m living in the future. Weird statement, but I’m supposed to feel like living in the present, aren’t I? What I’m trying to say is that with the Internet of Things, Artificial Intelligence, blockchain, quantum computing, and other technologies, our daily lives have become truly different, and we have somehow, evolved as a species.
Everything is digital, everything is about computing. It is believed that over 2.5 quintillion bytes (2.5e+9 GB) of the data is created every day! How are we keeping up with this pace? How do computers store data?
Data, data, data
Computers are these devices that receive, process, store, and output data. Here, we will focus on the storing part. 0s and 1s are quite famous for this. At its core, a computer operates in this binary system, but how thought? How is it that images, videos, documents, apps, or music can be stored in just a sequence of zeros and ones?
I didn’t understand that either until some days ago. The simplest type of data to explain for me, are images. The word pixel is formed by two parts: picture and element. A group of pixels are therefore, the elements that an image is made up of. Now, entering into the computing context a *bit more, a pixel is also a sequence of values. For color images, these values are called RGB, which stands for Red, Green, and Blue. In a given proportion, these values can create different colors and tones, and when more pixels with these values group together, they create an image with color.
Here when we say values, we refer to numbers. An example of an RGB value is (253, 78, 141), which creates a pinkish color. So let’s pay attention to these numbers: they can be represented in a binary code!

If you’ve ever created or learned a strange language to tell secrets to your friends, you know that you needed to create an equivalence for what each letter was in the secret language and in English (or the language that you normally speak).
Well, when transforming RGB values, or any other numbers into binary code (0s and 1s), we also have these kinds of equivalences. The most common system to do this, is called UTF-8, which stands for “Unicode Transformation Format — 8 bits”.
Before we get confused with the name, a bit is the basic unit of information in computing. It is either a 0, or a 1. A byte in contrast, is made up of bits, normally, a byte equals 8 bits, so 8 0s OR 1s. An example of a byte is “01101011”.
Therefore, the UTF-8 is nothing but that equivalence between information as we see it, and a binary code.
Once we’ve translated these colors into numbers, we can do the same with numbers into letters of DNA. The alphabet is fairly simple: A, C, G, T. These letters stand for the names of the chemicals: adenine, cytosine, guanine, and thymine. Normally, the order of these, would determine characteristics in living things, but here, it will be the for an image.
The most common equivalence that we can take into account for this is: A = 00 C = 01 G = 10 T = 11
Images
Here, we can already see that DNA is more effective, since one single letter can store two bits.
We come back to the question: how is it that a bunch of 0s and 1s can store text, apps, or videos? I was probably wrong when I said that images would be the easiest example to start with, but wasn’t it cool?
Now, the truth is that everything, from simple text, to 4k videos, can be stored with the same binary system, and thus, it can also be stored in DNA. The secret for this, is again the UTF-8, and our equivalence to DNA letters.
Here’s an example of a simple program I created to turn alphanumerical data into DNA:
#set variable with input text
original = input("Insert text or numbers: ")#convert text to binary values
binary = ''.join(format(x, '08b') for x in bytearray(original, 'utf-8'))#equivalence to DNA language
dna_dict = {
"00": "A",
"01": "C",
"10": "G",Ç
"11": "T",
}#separate into 2 bits
separated = []
for bit in range(0, len(binary), 2):
separated.append(binary[bit:bit + 2])#turn into DNA
dna = []
for x in separated:
for key in list(dna_dict.keys()):
if x == key:
dna.append(dna_dict.get(key))
final = "".join(dna)print(final)
Actual program
So a way in which we can easily translate digital stuff into DNA is by using Python, a programming language. I know, I know “one more language to remember”, but don’t worry, because being a programming language, it means that it’s somehow, not part of the equation, it’s just like a bridge that helps us (in this case) go from 0s and 1s to As, Cs, Gs, and Ts faster.
This said, I also know that it’s easier to understand all the steps involved in this if we have a simple series of steps. So, here’s what I did in order to turn an image into DNA. For those non-programmers, I didn’t include many things about the actual code.
- Where is the image: to make this step easier, I put the image on the desktop, then I copied the “file path” which looks something like this: “/Users/anasofiash/Documents/image.png”
- Import a library called PIL: this is what python uses to process images
- Get the RGB data: this step is simpler than it sounds because there’s a specific piece of code in python that allows you to do that, then you save that data into a list.
- Clean the data: in the previous step, python will hand you in a series of numbers, surrounded by a bunch of parenthesis and commas, and spaces, which we don’t need. Therefore, we can iterate through that data to get only what we want
- Turn into binary: I also thought this would be much more complicated, it turns out there’s already something in python called bytearray that makes this quite easy
- DNA dictionary: after that, we use a python dictionary to tell the program what the equivalence is for each DNA letter, we iterate through the binary sequence and turn each one of the two bits (00, 01, 10, or 11) into a DNA letter
- Saving the whole thing: if we wanted to output the final DNA sequence into the console, it would be a lot of information still, so my advice is that you write and open a new file for this
And that’s how you can turn an image into a DNA sequence. By the way, since a single image is still a lot of information, I had to use a very low resolution one. This is the image that I turned into DNA, and how its binary and DNA code look like.



Advantages
Great. We’ve turned data into DNA, so what? We know that a single letter of DNA can store two bits, and that for longer sequences, that translates into saving a lot of space, but is it worth it?
We can better appreciate the efficiency of storing data into this molecule when we talk about large amounts of information. One famous example is that a single gram of DNA can store 215 petabytes, or 215 million gigabytes, of data.
As previously mentioned, another advantage of storing data into this molecule can be found in the long-term. The disks in which digital data is currently stored can oxidate, which means that they need to be replaced quite often, compared to DNA, which doesn’t require anything but the right temperature.
Disadvantages
As I was saying, I think that as of now, this technology only has advantages if we’re willing to store the data for a long time. This is simply because retrieving the data is not that easy, in my opinion.
So when you store it, you need to use programs like the one I created, and then synthesize (print/produce/write) that DNA. It’s not that writing DNA is easy, but reading it can indeed be more complex, compared to how we read digital data today.
In the world of genomics, reading DNA is called “sequencing” DNA. Apart from requiring a special machine, this process can be prone to errors and isn’t as fast as when you read a file that you stored in the cloud.
The hope is that these reading and writing technologies continue becoming cheaper and more accurate, as they have been doing as of now. In that case, we could maybe see a future in which you and I consider storing our data into DNA rather than into the cloud.
From bio to stuff
Here’s when we’re really entering the world of DNA of Things. I hope I’m not disappointing you by saying this, but DNA of Things is this concept of storing data into DNA, and then put that DNA into every day objects.
These objects can go from plants to 3D printed objects. I don’t know about you, but this actually blows my mind quite a lot. We aren’t only re-imagining objects, but also living things.
In the case of plants, this may actually be a little more obvious. Plants are living things, living things already have DNA in their cells, that DNA is already storing data: biological data.
What we’re doing with DoT in this case, is just giving that DNA another purpose: to store digital data instead of biological one.
With 3D printed objects, though, things could get (just a little) more interesting.
Bunnies
Another advantage of storing data in this way? It can really take any shape! If you think about it, it could be the only type of storage that has this advantage.
The steps to store data into 3D printed objects is the following:
- Encoding: what we’ve talked about earlier with python. Experts take this to the next level using something called DNA Fountain, which is described later in the article
- Synthesizing: printing the DNA (having it in a physical form)
- Encapsulation: if we mixed the DNA directly with a 3D printing material, things would get difficult when the time comes to retrieve the data. Thus, researchers had to idea of encapsulating it into silica nanoparticles, resulting in silica particle-encapsulated DNA (SPED)
- Mix with PLA: polycaprolactone is a biodegradable thermoplastic polyester that offers low melting temperature. This is great because it will help us keep the DNA safe from melting, while creating the 3D printed object
I’m not the expert in 3D printing, but in principle, it’s just what it sounds like: creating three-dimensional objects using a machine. Another cool technology to keep an eye on for sure.
Data is useful if we can interact with it, so the next part of the experiment that these scientists did was retrieving the data directly from the 3D printed bunny.
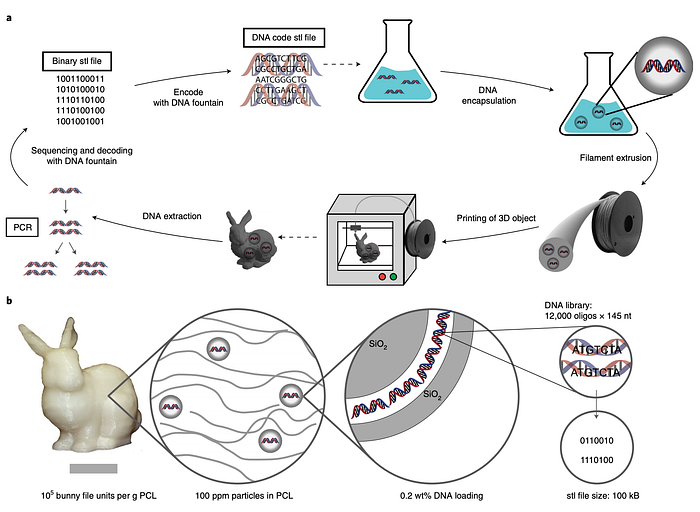
- Take a sample: they used approximately 3% of the object’s weight
- Take the SPEDs: using a compound called tetrahydrofuran (THF)
- Extract the DNA: using buffered oxide etch (BOE)
- “Clean” the DNA: using a standard PCR cleaning kit
- Sequence it: using a machine called sequencer
- Process the sequence: decode it using DNA fountain again
The DNA that they recovered corresponded to about 14,000 copies of the encoded file. The entire process took 4 hours, without taking sequencing into account, which took 17 hours.
That’s where we can definitely see room for improvement. In my opinion, DNA reading and writing is still too slow and expensive to take it to the market or use it in our daily lives.
Fountains
One of the problems of DNA synthesis and sequencing is that sequences with high GC content or long homopolymer runs (like AAAAAA) are difficult to work with, and so they’re prone to errors.
DNA fountain takes recent developments in coding theory and applies them to solve the specific constraints of DNA storage.
Worth-mentioning, in their paper, Yaniv Erlich and Dina Zielinski tell us that they stored an entire computer operating system, a movie, a gift card, and other computer files with a total of 2.14×10^6 bytes in DNA and they were able to fully retrieve the information without a single error!
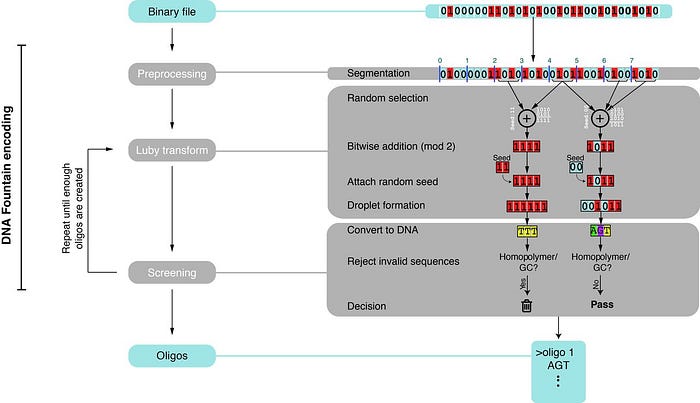
Their algorithm breaks the data into small non-overlapping chunks and uses another algorithm called “Luby transform” to compress the chunks into the final data that is encoded into DNA.
This invention definitely needs to be analyzed in more detail, but for now we know that they’ve also broken the record by cramming 215 Petabytes (1015 bytes) of data into a single gram of DNA!
The future
As I also stated in Biocomputing in a Nutshell, I think that DNA data storage is an absolutely great idea. Still, there are some challenges that we need to overcome with synthesis and sequencing.
I personally see big tech companies probably making use of DNA data storage since it would be worth it to store huge amounts of information in a very small amount of space, without having to worry too much about the hours needed to retrieve that data.
As of some other concerns, I think that security could be a very important one. We are just beginning to understand and create these applications of biology, so we haven’t thought very well about the security mechanisms that Google would need to have against biohackers.
Apart from thumb-drives, one of the things that I’m really looking forward to, is having an actual genealogical tree in my backyard, that actually contains all the memories from my great-great grandparents. Maybe it would just be a nice expensive present, but maybe I could actually have access to that sequencer to make use of the data, who knows?

Hey! I’m Sofi, a 16-year-old girl who’s extremely passionate about biotech, human longevity, and innovation itself 🦄. I’m learning a lot about exponential technologies to start a company that impacts the world positively 🚀. I love writing articles about scientific innovations to show you the amazing future that awaits us!
Twitter | LinkedIn | Website | Podcast | Newsletter